MultiWorld: Elastic Collective Communication for Model Serving
A scalable, fault-tolerant extension of collective communication libraries (CCLs) — designed for the next generation of ML inference.
What is MultiWorld?
MultiWorld is a research framework developed by Cisco Research that extends traditional collective communication libraries (CCLs) like NCCL to support elasticity and fault tolerance — two essential properties for scalable model serving. While not a model-serving framework itself, MultiWorld enables model-serving systems to dynamically scale and remain resilient in the face of failures.
Why MultiWorld?
Modern machine learning workloads, especially inference for large-scale models, have unique demands that traditional CCLs were not designed to meet:
- ❌ Static process groups: Once a group is initialized, it can't change.
- ❌ Single fault domain: Failure of one worker often brings down the whole group.
- ❌ Inflexibility: Adding new workers requires a full reinitialization.
MultiWorld addresses these challenges by:
- ✅ Allowing a worker to participate in multiple "worlds" (process groups).
- ✅ Enabling online scaling and fine-grained fault isolation.
- ✅ Supporting asynchronous, non-blocking operations to avoid deadlocks.
How does MultiWorld work?
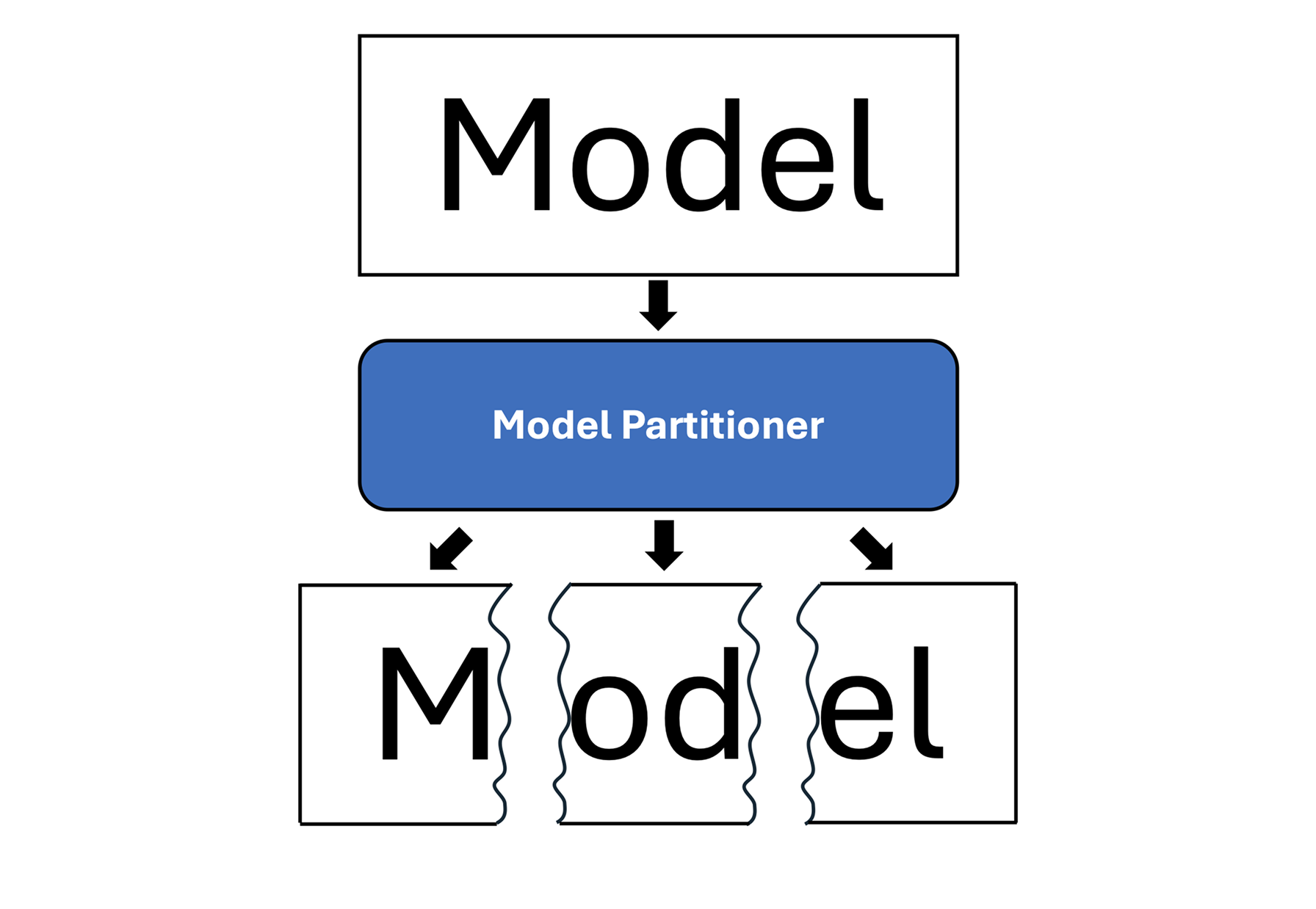
(a) Model partitioning
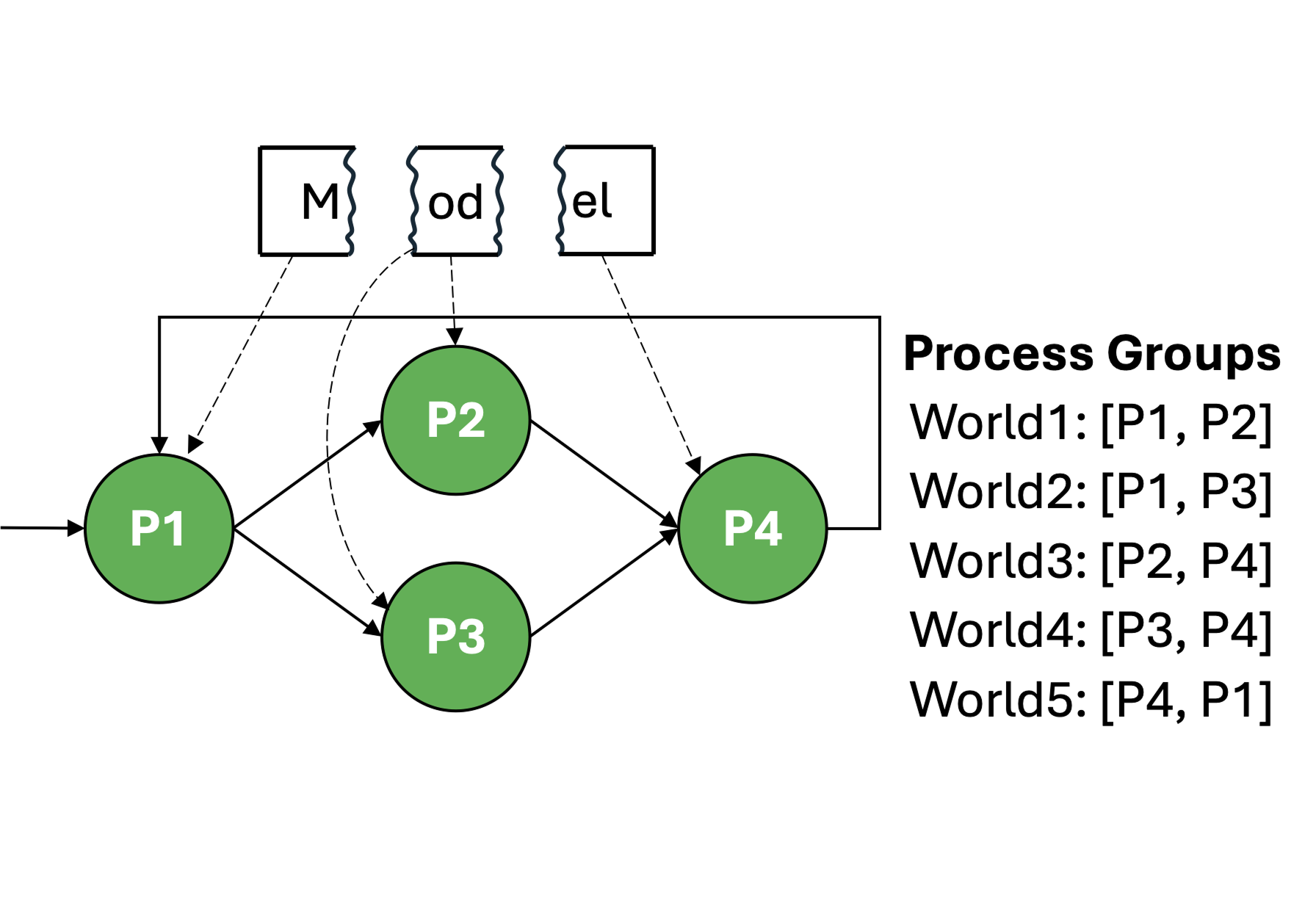
(b) Normal state
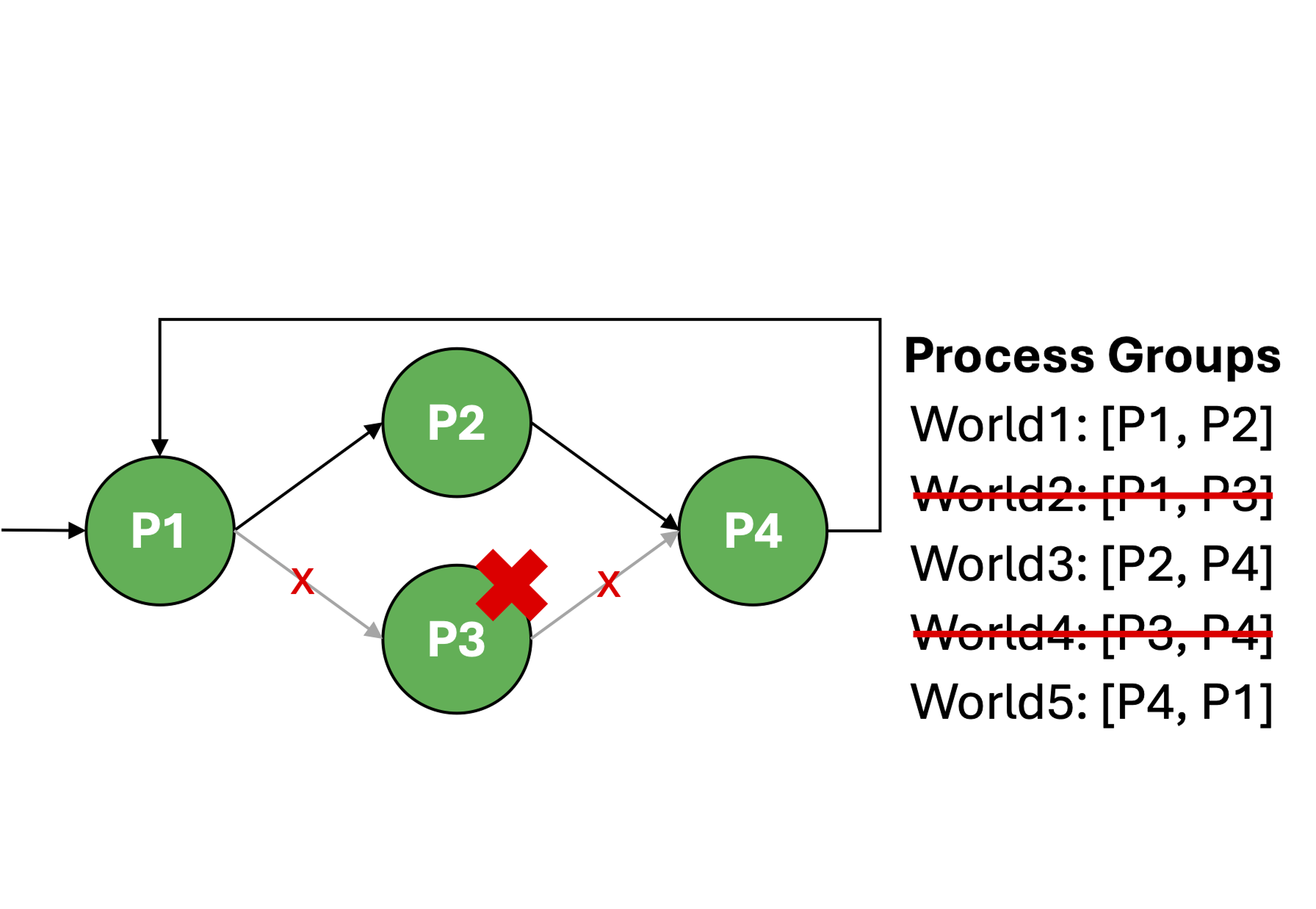
(c) Worker failure
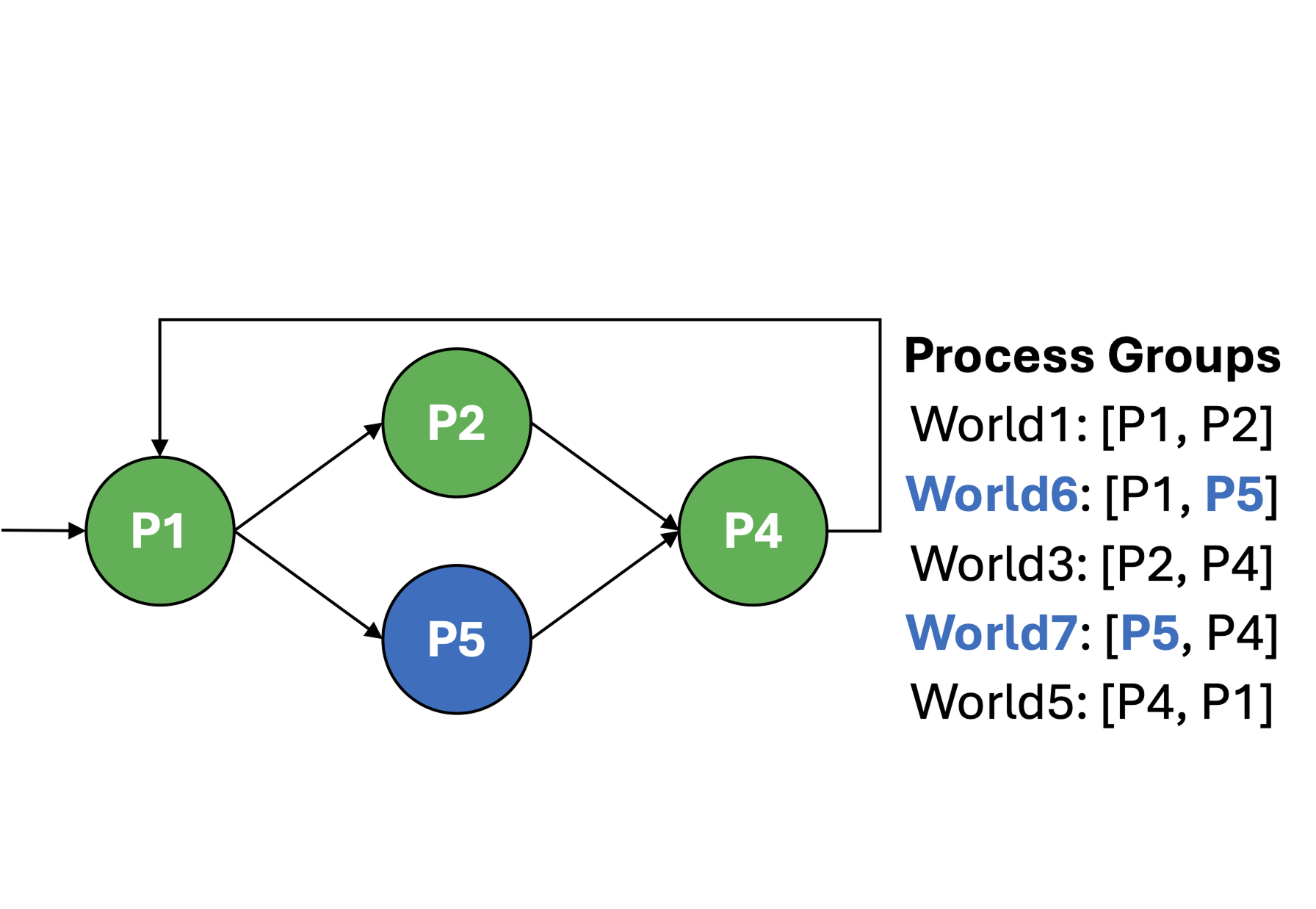
(d) Failure recovery
The figure above shows a conceptual overview of how MultiWorld enables elastic and resilient model serving through flexible deployment and dynamic communication. In (a), a machine learning model is decomposed into multiple partitions, each representing a stage in the inference pipeline. We assume that there exists a model partitioner. In (b), these partitions are then deployed across multiple worker processes, which handle different parts of the computation. For example, the middle partition is deployed redundantly across two workers to balance load and increase throughput.
To facilitate communication among these distributed workers, MultiWorld forms logical process groups, known as "worlds," between pairs of connected workers. Each world operates independently, allowing the system to route data through multiple execution paths and better tolerate imbalances or failures (as shown in (c)). This fine-grained mapping of model stages to workers, and workers to process groups, forms the backbone of MultiWorld’s support for horizontal scaling and fault isolation.
By decoupling model partitioning from physical deployment and introducing multiple communication groups, MultiWorld enables flexible, robust serving pipelines that can scale out bottlenecked stages and recover from failures without interrupting the broader service (as shown in (d)).
Key Features
- 🧩 Elasticity: Dynamically add or remove workers at runtime.
- 🛡️ Fault Isolation: Worker failures only impact the process groups they belong to.
- 🚀 High Performance: Achieves near-baseline throughput (1.4–4.3% overhead).
- 🔁 Multi-world Support: Each worker can belong to multiple overlapping groups.
- 🔗 PyTorch-Compatible: Seamlessly integrates with PyTorch's distributed module.
Architecture Overview
MultiWorld is implemented as an extension to PyTorch's distributed infrastructure and includes:
- World Manager: Handles creation and teardown of process groups.
- World Communicator: Supports non-blocking collective operations across worlds.
- Watchdog: Monitors worker liveness using PyTorch’s TCPStore.
This architecture enables robust communication patterns while preserving high GPU utilization and performance.
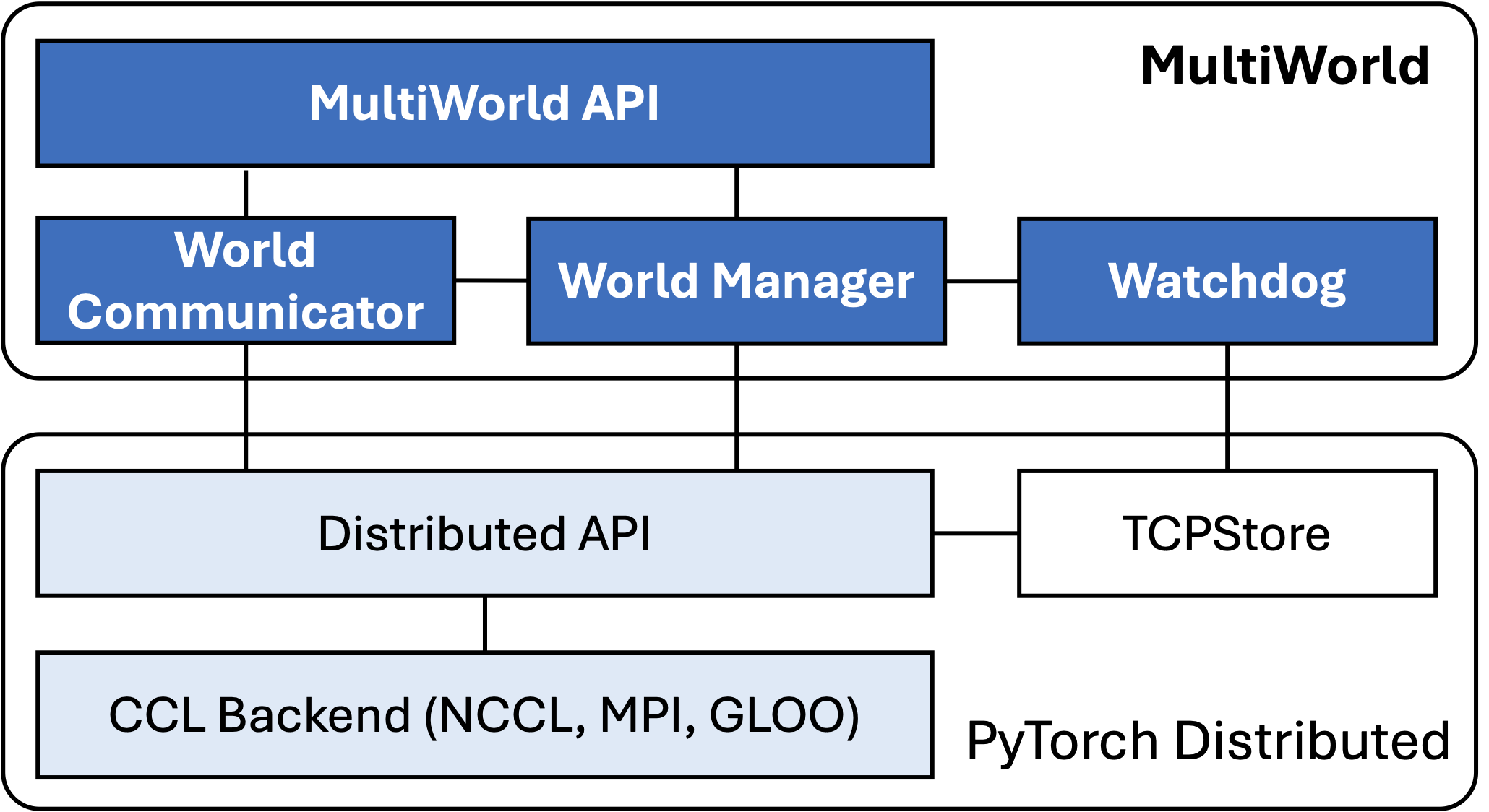
MultiWorld architecture
Performance & Evaluation
MultiWorld has been evaluated across GPU-to-GPU and host-to-host scenarios using NCCL and PyTorch. Key findings:
- Minimal performance degradation (<5%) even with dynamic scaling.
- Fast online worker addition with no impact on active worlds.
- Full fault isolation demonstrated in real testbeds (AWS VMs, V100 GPUs).
Target Use Cases
- Resilient inference infrastructure for large-scale machine learning models
- Distributed ML frameworks requiring dynamic scaling and fault isolation
- Custom model serving systems seeking fine-grained control over GPU communication
- Research prototypes exploring advanced communication patterns in PyTorch
Project Details
- 💻 Repository: GitHub – pymultiworld
- 📄 Publication: Read the paper on arXiv
- 🧠 Framework Type: Extension to PyTorch’s distributed communication backend
- 🔧 Implemented In: Python (with PyTorch v2.2.1)
- 🧩 Dependencies: Compatible with NCCL, GLOO, and other PyTorch CCL backends
- 🎤 Related Event: the Cisco Research AI Inference Infrastructure Summit
Contributors
- Myungjin Lee: Project maintainer / developer
- Rares Gaia: Developer
- Pranav Gadikar: Intern